
Hittil har datavarehuset vært det naturlige lagringsstedet for innsamlede data, men strikken er allerede strukket langt. I disse Big Data-tider må vi tenke nytt, og Data Lake er svaret, hevdes det.
«Vi ser at markedsføringsfaget er i vesentlig endring blant annet basert på endrede kundebehov, ny kundeadferd og teknologiske muligheter. Vi har derfor høyt fokus på analyseområdet og jobber med avanserte algoritmer på store mengder kundedata for å gi oss nødvendig innsikt til å utvikle relevant kommunikasjon til våre 1,1 million kunder,» sa Solveig Bratli Skjerven, Segmentleder i Storebrands markedsavdeling på Norges Markedsanalyseforenings Big Data Seminar i juni.
Storebrands markedsavdeling fremstår som et godt eksempel på hvor sentralt Analytics har blitt for forretning og hvor viktig det er å ta vare på kundedataene. Ettersom vi blir stadig mer datahungrige, og analytikerne gjør sitt inntog i sentrale forretningsprosesser, blir IT og datavarehusavdelingen utfordret på hvordan nye og endrede databehov kan imøtekommes raskere.
Datavarehuset har til nå vært det naturlige stedet å strukturere data til analyseformål, men teknologien og konseptet har sine begrensninger. I kjølvannet av den nye Big Data-teknologien har det dukket opp et nytt konsept, Data Lake, som hevdes å være løsningen på de mange uløste utfordringene innen BI og de nye behovene knyttet til Big Data. Noen definerer Data Lake som et eget datavarehus for Big Data, andre hevder Data Lake vil erstatte datavarehuset helt. Svaret ligger i deres ulike karakteristika. La oss starte med konseptenes 101:
Datavarehus 101
Datavarehus-konseptet ble introdusert på 80-tallet av blant annet Barry Devlin, og ikke minst Bill Inmon, som er anerkjent av mange som «datavarehusets far». Flere sentrale datavarehusprinsipper har dog sin opprinnelse fra helt tilbake til 60- og 70-tallet, blant annet drevet frem av General Mills, ACNielsen og IRI.
Det finnes flere godt etablerte definisjoner av et datavarehus, hvorav en av de enkleste er formulert av datavarehusguruen Ralph Kimball slik: «Et datavarehus er en kopi av transaksjonsdata spesielt strukturert for spørring og rapportering». Begrepet «transaksjonsdata» er noe omdiskutert, men kommer antagelig av at de fleste operasjonelle IT-løsninger har transaksjonsfokus. Inmons formulering er mer konkret på datavarehusets form: «…en emneorientert, integrert, tidsrelatert og ikke-volatil samling av data til støtte for ledelsens beslutningsprosesser.» Inmons definisjon er antagelig den mest anerkjente, til tross for unøyaktigheten som ligger i at datavarehusets bruksområder har vokst langt utover kun beslutningsstøtte for ledelsen.
Det finnes ulike referansearkitekturer innen datavarehus, men én ting er felles: Dataene trekkes ut fra de forskjellige kildesystemene, transformeres og tilrettelegges i en form som gir et best mulig underlag for analyse og rapportering. I datavarehuset har alle innsamlede data fått forståelige og entydige navn og gode definisjoner (emneorientert). De henger sammen på tvers av prosesser, organisatoriske enheter og opprinnelige datakilder (integrert). De blir oppbevart permanent (ikke-volatil), med tidsstempling og versjonering av endringer over tid (tidsrelatert).
Et datavarehus består som regel av flere datalag, hvorav følgende 3 er mest vanlig: Staging, som er et forkammer der dataene kopieres inn fra kildesystemene slik at den tunge databearbeidingen videre ikke overbelaster kjerneprosessene, Enteprise Layer, der dataene ligger komplett integrert på sitt mest detaljerte nivå, samt Data Marts, som er ferdigkalkulerte data (kalkulert opp fra Enterprise Layer) tilrettelagt for spesifikke analyseformål.
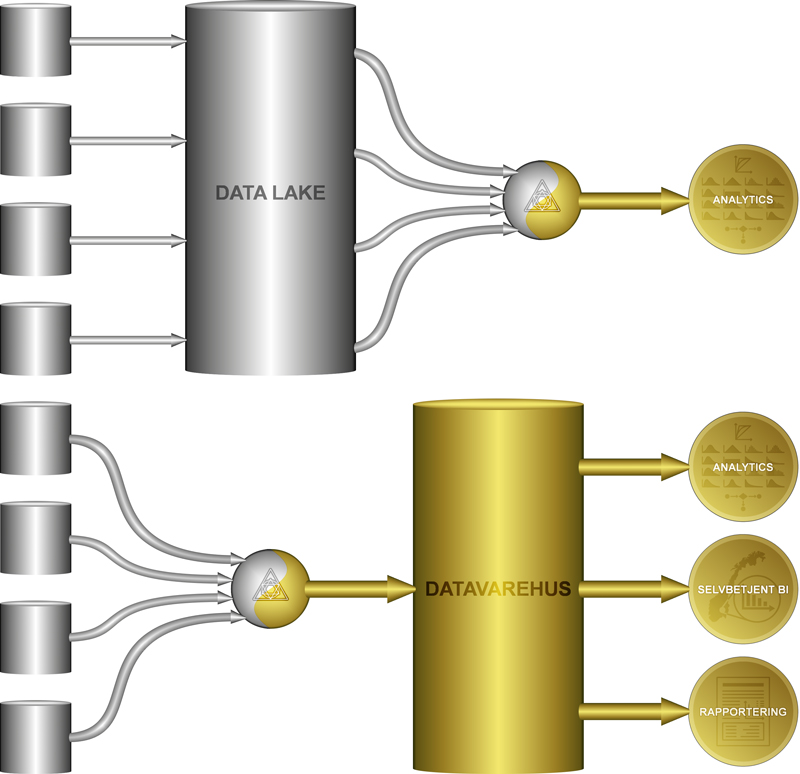
Data Lake vs. Datavarehus: Data Lake oppbevarer dataene i sitt råformat slik de ligger i kilden, og foredlingen skjer i etterhånd (late binding). I datavarehuskonseptet blir dataene foredlet på vei inn (early binding), slik at de ligger ferdig tilrettelagt for definerte bruksområder.
Data Lake 101
Data Lake-konseptet går ut på å kanalisere data fra alle tenkelige datakilder inn til et felles lagringsområde, tilgjengelig for både kjente og foreløpig ukjente analyseformål. Beskrevet på dette overordnede nivået blir definisjonen relativt lik datavarehuset, men det er spesielt én vesensforskjell: På vei inn i et datavarehus, blir dataene foredlet, mens en Data Lake oppbevarer dataene på sitt opprinnelige råformat. Med en Data Lake bearbeides ikke dataene før de hentes ut til et spesifikt formål. Dette kalles gjerne late binding eller schema on read (mens et datavarehus i denne kontekst blir early binding / schema on write).
Begrepet Data Lake ble introdusert i 2010 av James Dixon, CTO i Pentaho, i forbindelse med lanseringen av deres første Big Data-løsning på Hadoop-plattformen. Hadoop er bl.a. en NoSQL-database (Not Only SQL), som innebærer full fleksibilitet i forhold til datatyper og struktur (les om Hadoop i Analysen nummer 1 2015 side 34 – 37). Denne typen datalagringsteknologi ansees gjerne som en forutsetning for Big Data og Data Lake, da disse konseptene tar inn over seg at mange datakilder er mindre strukturerte og fluktuerer mer enn det som forutsettes av tradisjonelle databaser (typiske SQL-databaser) som de fleste datavarehus er basert på.
Som med alle trendord, så blir også Data Lake-begrepet adoptert og benyttet av løsningsleverandører. Men med en gang vi begynner å bearbeide og sammenstille dataene til en løsning, så er vi utenfor selve Data Lake-konseptet. Da har vi, om vi skal bruke datavarehusterminologien, tilrettelagt en Data Mart.
Early Binding – Big Bucks
Tenk deg at du stiller interessentene følgende spørsmål: «Skal vårt felles analyseunderlag inneholde alle data fra alle kilder, i alle fall de vi tror det er en viss sannsynlighet vi kan få behov for, eller skal vi kun samle inn de dataene vi vet p.t. vi har behov for og kan forsvare forretningsnytten av?» Dersom det ikke hadde vært et kostnadsspørsmål, så ville nok flertallet svart førstnevnte alternativ. Vi vet jo ikke hva vi kan få behov for i fremtiden og da er det jo best å sikre seg ved å ta vare på alle data. Men det var for stort omfang som førte til at mange datavarehusprosjekter feilet på 80- og 90-tallet. Mang en lederbonus gikk nok fløyten på grunn av store budsjettoverskridelser, og det finnes fortsatt ledere som føler sterkt ubehag når de hører begrepet datavarehus.
Det er early binding-prinsippet som gjør datalastingen til datavarehuset kostbart og tidkrevende. Datavarehuskonseptet dreier seg om at dataene fra de mange datakildene berikes, sammenstilles og tilrettelegges slik at de gir et mest mulig riktig og helhetlig datagrunnlag for alle nåværende og tenkelig fremtidige analyse- og rapporteringsformål. Utfordringen med dette er at vi på forhånd må bestemme hva som er «riktige» transformasjonsformler og hvordan dataene skal struktureres optimalt. Dette er både tidkrevende og vanskelig, og det er heller ikke til å stikke under stol at det er varierende kvalitet på en del datavarehusleveranser. Siden et datavarehus i praksis er under kontinuerlig utvikling, vil de fleste datavarehus bære preg av både gode og dårlige tider (påvirket av faktorer underveis, som finansiering, styring, kompetanse etc.), litt på samme måte som man kan lese av gode og dårlige sommere på årringene til et tre.
Konsekvensen, slik brukerne opplever det, er at datavarehuset på langt nær inneholder alle ønskelige data, samt at nye ønsker og behov må gjennom streng prioritering og har lang implementeringstid. I praksis må man fremvise et godt business case for å få gjennomslag for å ta inn nye data i datavarehuset, og her står vi ved en sentral problemstilling for analytikerne: Vi vet egentlig ikke hvilken verdi dataene har før vi har dem tilgjengelig, og selv da ser vi kun deres verdi basert på de hypoteser og forretningsspørsmål vi foreløpig kjenner til. Denne utfordringen blir ikke noe mindre i en verden av Big Data. Mulighetene er enorme, og vi har gode indikasjoner på at det ligger mye gull i disse dataene, men vi har ikke kapasitet til å hente ut alt. Selv om vi foreløpig ikke har mulighet til å raffinere det hele, ønsker vi derfor ikke å kvitte oss med råmaterialet om vi kan finne et rimelig sted å oppbevare det. Det er her Data Lake kommer til sin rett!
Late Binding – Big Geeks
Siden Data Lake baseres på rimelig lagringsteknologi og laster dataene inn rått uten omfattende transformasjoner, gir dette en reell mulighet til å samle inn og ta vare på alle data. Og med alle data tilgjengelig, så er det vel bare å dykke ned i dataene når vi har behov, eller…? Feil! Her må det nok en brukbar dose alkymi til for å forvandle datamassen til gull, og alkymistene blir populært kalt Data Scientists. Siden dataene ligger i sin opprinnelige form, kreves omfattende innsikt og grundig etterforskningsarbeid for å tolke og forstå dataene: Dataene er sjeldent intuitive, de forskjellige datakildene har ulike kodeverk og terminologier, og dokumentasjonen er ofte fragmentert og mangelfull. Big Data-aspektet øker kompleksiteten ytterligere, med blant annet lite strukturerte tekster, loggdata, klikkstrømmer, sensordata etc.
I et datavarehuskonsept står datavarehusarkitekter og -utviklere for arbeidet med å tolke og tilrettelegge dataene i forkant av analyseprosessene, mens med Data Lake-konseptet blir dette opp til den enkelte Data Scientist, eventuelt en dataekspert som jobber dedikert med analytikerne. Uansett konsept og rolle, så kreves inngående forretningsinnsikt på tvers av prosessene, detaljert teknisk forståelse av alle datakildene, samt god kunnskap og erfaring innen databearbeiding.
Spørring og analyse på data i en Data Lake krever ekspertise og er ikke noe en vanlig sluttbruker vil kunne mestre. En Data Lake i kombinasjon med spørre- og analyseverktøy kan kalles Self-service Analytics, som indikerer at Data Scientists kan hente ut og analysere det de trenger på egenhånd. Dette er dog ikke det samme som Self-service BI. Poenget med BI er nettopp at hovedvekten av brukerne ikke er dataspesialister, så terskelen for en selvbetjent BI-løsning må være vesentlig lavere. Kryptiske data, inkonsistens, manglende koblinger etc. kan ikke aksepteres i en BI-løsning. Derfor må analyse og rapportering for denne brukergruppen baseres på datavarehusprinsipper. Stadig mer BI blir også operasjonalisert og automatisert (automatiske beslutninger etc.), og slike prosesser krever struktur.
På et tidspunkt i fremtiden vil antagelig spørreteknologien blir så intelligent at den både forstår det vi spør om, samt klarer å finne frem i og tolke ustrukturerte og udefinerte data rett på egenhånd. Såkalt Cognitive Computing er under rasende utvikling. Det er likevel et stykke frem før vi kan overlate maskinene til seg selv. Om vi da ønsker det?
Når computeren spytter ut svaret «42», så er det en fordel å forstå både spørsmål og resonnement. I filmen «2001: A Space Odyssey» sa stjerneskipets computer HAL 9000: «No 9000 series has ever made a mistake or distorted information. We are all, by any practical definition of the word, fool-proof and incapable of error»…Men mens vi venter på at HAL skal overta databearbeidingen (og beslutningene), så vil behovet for gode Data Geeks være prekært enten vi snakker om early binding eller late binding.
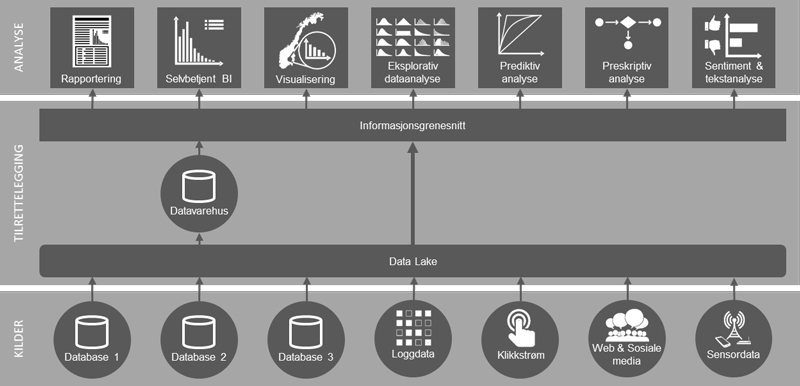
Overordnet (forenklet) referansearkitektur som kombinerer Big Data med tradisjonell BI.
Think Big – Start Big
Mange av de tidlige datavarehusprosjektene hadde fokus på å bygge datavarehuset «ferdig» først, for deretter å tilrettelegge Data Marts og slippe til brukerne (såkalt top-down-tilnærming). Dette resulterte gjerne i gigantprosjekter som kunne pågå i flere år uten at brukerne så resultater av investeringen. I dag er det mer vanlig å få kontroll på omfanget ved å dele opp leveransene i henhold til dataområder, og at dataområdene blir tilgjengeliggjort helt ut til Data Marts og brukergrensesnittene for hver leveranse (bottom-up eller hybrid). Dette betyr at brukerne ikke får alt de har bestilt på en gang, men at sluttbrukerløsningene leveres inkrementelt etter hvert som dataområdene står ferdig. «Think Big – Start Small,» er mottoet.
Men hovedutfordringen med et datavarehus er likevel ikke løst: Uansett tilnærming, så tar det fortsatt lang tid fra et databehov oppstår til dataene ligger klar til bruk. Med en Data Lake kan ekspertbrukere få dataene tilgjengelig ganske umiddelbart etter at behovet har oppstått. Vi snakker jo i utgangspunktet kun om å laste inn dataene rått, uten kompliserte transformasjoner. Når det først er investert i kompetanse og teknologi for å demme opp en Data Lake, så kan det til og med forsvares å ta vare på data selv før vi vet om vi kommer til å få bruk for dem (dette er gjerne referert til som unknown unknowns).
Når dataene først ligger i en Data Lake, kan vi når som helst på et senere tidspunkt føre de dataene vi har behov for videre inn i datavarehuset. Sett fra et datavarehusståsted, blir Data Lake å betrakte som et Staging Layer.
En del data vil det likevel aldri bli relevant å ta inn i datavarehuset. «Not all data needs to fly first class,» sa Martha Bennett fra Forrester Research, keynote på GOBI2015. Dette gjelder spesielt innen Big Data, der dataene prosesseres best på Hadoop eller lignende teknologiplattformer.
I en referansearkitektur som favner både tradisjonell BI og Big Data, kan det være naturlig å tenke seg en Data Lake i bunn som både leverer data til datavarehuset og samtidig fungerer som et selvstendig datalager det kan gjøres spørringer og analyser mot direkte. Data Scientists kan brøyte vei for andre, ved å gradvis tilføre semantikk på toppen. Om Data Lake kommer til å overta for all staging vil nok variere, men dagens stage er normalt bare en temporær mellomlagring, mens en Data Lake vil kunne beholde dataekstraktene permanent på originalformatet. Det kan være en stor fordel, siden datavarehuset sjelden tar inn alt, samt at dataene mister noen av sine opprinnelige egenskaper og nyanser i transformasjonene på vei inn i datavarehuset.
Data Lake-konseptet har også sin andel av kritikere, hvorav mye av kritikken er knyttet til mangel på struktur og styring. Navnet gir riktig nok litt feil assosiasjoner, for som Martha Bennett sa på GOBI2015: «Når du heller en bøtte med vann ut i en innsjø, så vil du aldri senere klare å fylle opp en bøtte med det samme vannet.» Men Data Lake er ikke ekvivalent med dataanarki – dataene må selvfølgelig også administreres i dammen. Data Lake Governance, med metadatahåndtering og annen basisadministrasjon, er fullt mulig og en relativt rimelig investering i denne kontekst. Data Lake-konseptet holder således vann.
Annonse

Annonse
