
Innen CEM er prediktiv modellering eller maskin læring1 av stor betydning, for å optimalisere forretningsmessig verdi gjennom å vinne flere kunder, øke kundetilfredshet og oppnå lojale kunder.
Maskinlæring er ikke noe splitter nytt. Algoritmer som lærer av datasett og bygger statistiske modeller for å utforske data, predikere utfall og komme med anbefalinger, har eksistert lenge. På 70-tallet og starten av 80-tallet var mange dataingeniører, informatikere og statistikere opptatt av kunstig intelligens. Fremveksten av maskin-læring er i stor grad knyttet til dette, selv om de eldste modellene og algoritmene er mye eldre. Feltet fikk imidlertid oppsving først på 90-tallet, noe som kan henge sammen med at fagfolkene på dette tidspunktet hadde fått med seg de to første Terminator-filmene. Av frykt for å lage Skynet basert på mangelfullt grunnlag, tok de i bruk maskinlæring til å håndtere mer praktiske problemstillinger som for eksempel prediksjon og klyngeanalyse.
Modellene innen maskinlæring brukes i dag innenfor en rekke forskjellige felter, for eksempel optimalisering av aksjeporteføljer, bilde- og språkgjenkjenning, avdekking av svindel, strukturering av ustrukturerte data, stemningsanalyse av trafikk på sosiale medier, databasert kundesegmentering og markedsføring, prediktivt vedlikehold, automatisk webdesign og anbefaling av menyvalg på restauranter. Flere og flere bedrifter benytter prediktive modeller i kundedialogen (embedded analytics). Jeg vil her dele innsikt i noen mye brukte algoritmer, som ofte benyttes innen prediktiv modellering for CEM, innen churnprediksjon, up-sale, cross-sale og optimalisering av praktisk bruk av kommunikasjonstjenester.
I prediktive analyser benyttes historiske data til å forutse fremtidig adferd, men også til å finne sannsynlige forklaringer på det som har hendt eller er i ferd med å skje. Jeg vil derfor også komme inn på noen mye benyttede maskinlæringsalgoritmer innen prediktiv modellering: logistisk regresjon, Random Forest og neural network.
Logistisk regresjon
Logistisk regresjon er den mest brukte regresjonsanalysen når den avhengige variabelen er todelt. Metoden kan brukes til å teste hypoteser om variablers effekt på en todelt avhengig variabel og til å beregne sannsynlighet for at en enhet med bestemte kjennetegn tilhører en bestemt gruppe. Logistisk regresjon kan også benyttes til å beregne sannsynligheter for at noe bestemt vil skje eller ikke (churn, up-sale, cross-sale).
Den avhengige variabelens egenskaper er avgjørende for når man kan anvende logistisk regresjon. Forutsetningen for OLS-regresjon (minste kvadrats metode) er at den avhengige er en kontinuerlig variabel på intervall- eller forholdstallsnivå (men også tilfeller der man forutsetter at det som strengt tatt er en variabel på ordinaltallsnivå, likevel kan behandles som om den var på intervallnivå hvis den har minst 5 kategorier). Logistisk regresjon kan derimot anvendes også på avhengige variabler som er på nominal- eller ordinalnivå. Forskjellen mellom lineær og logistisk regresjon er at logistisk regresjon har en annen grunnleggende logikk, som gjør resultatene noe mer utfordrende å fortolke. Koeffisientene har en annen mening. I logistisk regresjonen beregner man ikke hvor mye Y endrer seg for hver enhets endring i X. I stedet beregner man hvor mye den naturlige logaritmen til oddsen for Y=1 endrer seg for hver enhets endring i X. I logistisk regresjon er det en annen estimeringsmetode: ikke OLS, men maximum likelihood (sannsynlighetsmaksimering). R2 erstattes med andre mål på modellens forklaringskraft, pseudo R2.
Styrker og svakheter ved logistisk regresjon
Denne formen for regresjon er oftest brukt når man mistenker at utfallet av et forhold ikke er lineært relatert til de uavhengige variablene i datasettet. Logistisk regresjon er dermed et alternativ til lineær regresjon, basert på logit-funksjonen, som er et forhold mellom oddsen for suksess og oddsen for å mislykkes. Til tross for sitt manglende behov for avhengighet av forutsetninger om linearitet, har logistisk regresjon sine egne forutsetninger og egenskaper som gjør den ugunstig i visse situasjoner. I motsetning til lineær regresjon, kan logistisk regresjon bare brukes til å forutsi diskrete funksjoner. Derfor er den avhengige variabel av logistisk regresjon begrenset til et diskrete antall sett. Denne begrensningen i seg selv er problematisk, da dette er uoverkommelig for prediksjon av kontinuerlige data. Et tilleggsproblem med denne egenskapen i logistisk regresjon, er at fordi logit-funksjonen i seg selv er kontinuerlig, kan noen brukere av logistisk regresjon misforstå og tro at logistisk regresjon kan brukes til kontinuerlige variabler.
Hvis man bruker lineær regresjon på en dikotom avhengig variabel (0 eller 1) får man to problemer. For det første urealistiske prediksjoner over 1 eller under 0, og for det andre heteroskedastisitet. Logistisk regresjon løser begge disse utfordringene, og er en robust metode som har flere statistiske mål for validering av modellene.
Random Forest
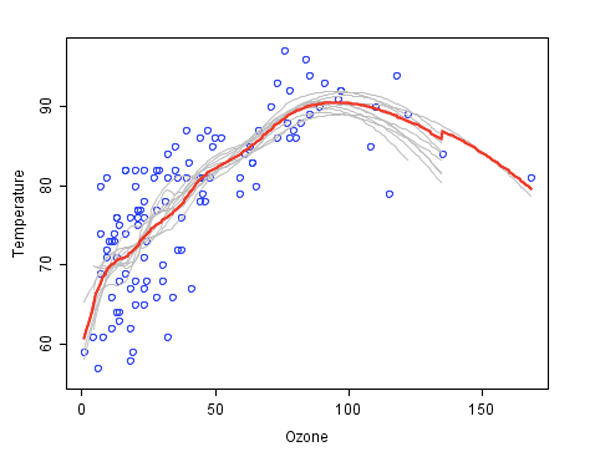
Random Forest er en ensemble modell, og kan også bli sett på som en form for nearest neighbor prediksjon (Breiman, 2001). Ensemble modellering er en splitt-og-hersk metode som sagt på en enkel måte benyttes for å øke prediksjonsevnen. Det viktigste prinsippet bak ensemble-metoder er at en gruppe av ”weak learners” kan settes sammen, for å danne en ”strong learner”. Figuren nedenfor gir et eksempel på dette. Hver classifier, enkeltvis, er en ”weak learner”, mens alle classifiers sammen er en ”strong learner”. Dette er en metode som utnytter større deler av datamaterialet, også variabler som alene har liten betydning.
De blå sirklene illustrerer dataene som blir modellert. Man forutsetter at dataene representerer en underliggende funksjon i tillegg til støy. Hver enkelt individuelle «learner» er illustrert med en grå kurve. Hver grå kurve (en weak learner) fungerer som en tilpasning til de underliggende dataene. Den røde kurven (the ensemble «strong learner») kan ses på som en langt bedre tilpasning til de underliggende dataene.
Styrker og svakheter ved Random Forest
Random Forest algoritmer er raske på data prosessering, og er egnet til å modellere på ubalanserte datasett og datasett med missing verdier. Svakheten med Random Forest opptrer dersom algoritmen skal benyttes for regresjon, for algoritmen kan ikke predikere utover treningsdataene. I tillegg vil man kunne få problemer med over-tilpasning i datasett som har mye skjeve fordelinger.

Neural network
Nevrale nettverk er et fagområde innenfor kunstig intelligens/maskinlæring som er inspirert av hvordan hjernen er konstruert. I hjernen har vi milliarder av nevroner (eller nerveceller) som reagerer på sanseinntrykk som syn, lyd, lukt og som er koblet sammen med andre nerveceller for å sammen fortelle kroppen hvordan den skal reagere. Tilsvarende vil et kunstig nevralt nettverk ha tusenvis (eller millioner) av nevroner koblet sammen i ulike typer nettverk, og være i stand til å gjenkjenne mønstre i store datamengder.
Nevrale nettverk lærer ved hjelp av eksempler, og vil derfor bli bedre med flere erfaringer. F.eks eksempel vil et nevralt nettverk lære hvordan et ansikt ser ut ved hjelp av tusenvis eller millioner av eksempler. I et dypt nevralt nettverk vil det være flere lag, hvor hvert lag lærer en høyere abstraksjon enn det forrige. Desto flere lag, desto mer avanserte mønstre kan læres.
Styrker og svakheter ved neural network
Den største fordelen med nevrale nettverk er deres evne til å håndtere komplekse sammenhenger mellom input og output av store datasett. I tillegg kan nevrale nettverk også dra nytte av å være i stand til å lære ettersom de får mer erfaring i å analysere data. Ut over dette kan de analysere lineære og ikke-lineære sammen-henger i dataene.
En svakhet med neural network er utfordringen med black box modellering som gjør resultatene vanskelige å fortolke. Flere av de store software leverandørene som SAS og IBM, og bruk av kodespråk som for eksempel R eller Pyhton, gjør det imidlertid mulig å åpne opp black box gjennom å utvikle klassifikasjonstrær som beskriver neural networks prediksjoner.
Bruk av prediktiv modellering basert på machine learning algoritmer i CRM
Prediktiv modellering brukes mye i CRM til å modellere markedsmodeller som beskriver sannsynligheten for at en kunde vil ta visse valg. Valgene kan f. eks. være knyttet til kjøp eller kundelojalitet. For eksempel vil en mobiloperatør ha et sett med prediktive modeller for cross-sale, deep-sell og churn. Det er også nå vanlig at slike organisasjoner bruker uplift-modeller. En slik modell predikerer sannsynligheten for at en kunde kan bli innlemmet på slutten av en kontraktsperiode (forandring i churn sannsynlighet) i motsetning til en standard churn prediksjons modell.
Neural network brukt i kommunikasjonstjenester
Kunstig intelligens-teknologi har vært tilgjengelig i mange ti-år, men det er først nå man tydelig ser bruksområdene. Og det er innenfor nevrale nettverk man har sett de store gjennombruddene. Facebook, Apple, Google og Baidu (tilsvarende Google i Kina) ansetter nå de mest fremragende forskerne og satser store summer på kunstig intelligens. Resultatene er uttrykt gjennom lansering av oversettelsestjenester, digitale assistenter og tjenester som på ulike måter utnytter tekst-, tale- og bildegjenkjenning. Ut over dette kommer tjenester som utnytter store mengder sensordata. Bildet nedenfor illustrerer fremtidens museumsbesøk basert på kunstig intelligens.
Kunstig intelligens brukes derfor i dag i de aller fleste avanserte kommunikasjonstjenester, i bildetjenester og dessuten i personlige digitale assistenter som Siri, Cortana og Google Now. Også Facebook er bygget på kunstig intelligens. Til slutt kan Apple Watch nevnes. Her brukes kunstig intelligens for å foreslå relevante kommandoer slik at dialogen blir enklere, og ulempen knyttet til liten skjerm blir redusert.
Kilder: Wikipedia, neuralnetworksanddeeplearning.com, kdnuggets.com.
Annonse

Annonse
