
Foto illustrasjonsbilde: Susan Q Yin
Ved bruk av enkle skala-spørsmål vil man ofte se lite varians (forskjeller) i svarene. Et tabloid eksempel-spørsmål kan illustrere dette:
Hva er viktig for deg når du skal kjøpe ny bil? (skala)
- Miljø
- Sikkerhet
- Økonomi
- Design
- Kjøreglede
For mange vil alle alternativene oppleves som viktige, og flere svaralternativer scores høyt. Det finnes ingen mulighet for respondenten for å prioritere noe på bekostning av noe annet. Man kan da bli sittende med et datagrunnlag som gir lite og upresis informasjon. Samtidig har vi noen klassiske utfordringer med skalabruk, som kan forsterkes noe i denne type vurderinger, eksempelvis ulik tolkning av skalapunkter, ulike prioritering av bunnpunkt og topp-punkt, samt forskjellig forståelse av semantikk og språkvalører.
MaxDiff, eller Maximum Difference Scaling, er en teknikk som brukes i research for å prioritere preferanser blant et sett med egenskaper. Metoden er gjennom årene ansett å være noe av en gullstandard for dette formålet. Metoden baseres på enkel conjoint-metodikk (conjointly – samtidige valg), og baseres på prinsippet om «discrete choice», eller «prioritert valg»; man velger ett konkret valg fremfor ett eller flere alternativ.
MaxDiff har betydelig diskrimineringskraft, og er designet for å skille mellom egenskaper effektivt, noe som gjør den egnet for situasjoner der du trenger å identifisere de mest og minst foretrukne alternativene i et datasett.
Under følger et eksempel på hvordan ett MaxDiff-alternativ kan se ut for én respondent:
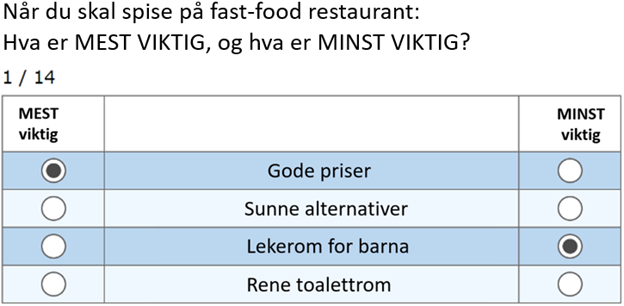
Respondenten vil typisk se 4-6 egenskaper vist i en rotasjon på 12-16 kombinasjoner. Dette fungerer fint i et standard spørreskjema, spesielt om man prioriterer gode innledninger og forklaringer.
(Antallet intervjuer som skal gjennomføres og antallet egenskaper som inkluderes i prosjektet er utgangspunktet for hvor mange egenskaper og antall rotasjoner som vises.)
Oppsett av egenskaper, intern logisk konsistens
Første skritt for å sette opp en MaxDiff-undersøkelse er å bestemme hvilke egenskaper som skal inkluderes. Dette er i hovedsak kundens egen oppgave: Hva vil vi vite? Hvilke egenskaper må vi ha med? Hvilke egenskaper er «nice to know» og kan droppes? Listen består gjerne av 15-20 egenskaper. Disse kan utledes basert på intern kompetanse/undersøkelser, på kvalitative undersøkelser, eller basert på andre kvantitative undersøkelser.
Noen punkter som kan vurderes ved oppsett av en liste med MaxDiff-egenskaper er:
- Intern logisk konsistens; husk at respondenten skal velge mellom egenskapene, og at forståelsen av hver egenskap skal være intuitiv og naturlig, og forstås i sammenhengen med de andre. Sørg for at alle egenskaper har omtrent samme «opplevde verdi».
- Pris- og kostnadselementer bør vurderes svært nøye før de går inn i en MaxDiff. Vurder i hvilken grad denne type egenskaper vil «slå i hjel» de andre, og dermed bidra til å gi mindre informasjon. Vi vet allerede at samme produkt er mer attraktivt når det er billigere.
- Bruk korte, enkle og tydelige formuleringer for alle egenskaper
- Bruk korte og presise innledninger og forklaringer
Design og oppsett av maxdiff
Et MaxDiff-oppsett skal programmeres og designes av en spesialisert programmerer/analytiker som kalkulerer antallet egenskaper vist per side og antallet kombinasjoner som er nødvendig for å gi undersøkelsen optimal intern validitet. Her spiller antallet intervjuer som skal gjennomføres også inn. Deretter setter programmerer opp undersøkelsen, med gode tekster og layout, slik at respondentens opplevelse blir best mulig. Undersøkelsen er da klar for felt.
Output
Resultater fra en MaxDiff beregnes av spesialist. Det er avanserte kalkulasjoner som ligger bak resultatene. I Norstat er vi ansvarlige for datainnsamlingen, mens våre kompetente samarbeidspartnere tar seg av analysearbeidet.
Verdiene i output kalles gjerne «nytteverdier», eller «utilities». Hver respondent blir henført en nytteverdi for hver egenskap. Nytteverdiene kan estimeres på forskjellige måter. Vi presenterer her to av de mest brukte:
- HB (Hierarchical Bayes) er fremdeles mest vanlig i bruk, og ansees av mange for å være en standard for utregning av MaxDiff-nytteverdier. Metoden er gjennomprøvd, og benyttet over mange år, men kan også oppfattes som noe utdatert. Uten å gå i for teknisk detalj kan det være hensiktsmessig å være oppmerksom på følgende:
- HB krever et godt balansert design for å være effektiv.
- HB er krevende i forhold til datakraft, og en gjennomføring kan i praksis ofte ta flere timer. Dette betyr blant annet at HB ikke kan rekalkuleres «on the fly», eksempelvis ved valg av undergrupper i en datavisualiseringsløsning.
- HB benytter i sine utregninger et gjennomsnitt for totalutvalget i de tilfellene der modellen ikke har data (ingen respondenter har sett alle kombinasjoner av egenskaper). Dette betyr at nedbrytninger aldri vil være helt «rene» (dersom de ikke kjøres spesifikt for den aktuelle undergruppen), de inneholder resultater fra hele utvalget. Dette har oftest mindre betydning i praktisk bruk.
- Output fra en HB-kjøring kan velges i ulike formater. Husk at dersom resultatene indekseres kan de ikke benyttes som sammenligning mellom nedbrytninger.
- PageRank er en annen metode for utregning av MaxDiff-resultater. Metoden er basert på avansert maskinlæring, og er utviklet av Google-gründere Larry Page og Sergei Brin. Den fungerer på andre prinsipper enn HB. PageRank benytter nettverkskalkuleringer som blant annet henfører numeriske vekter til alle egenskaper.
- PageRank har ikke det samme behovet som HB for et velbalansert design.
- PageRank er betydelig lettere å kalkulere, og krever ikke tilsvarende datakraft som HB.
- PageRank benytter nettverk-/maskinlæringsteknikk for beregningene, og har dermed ikke HB sin svakhet i måtte «låne» totalutvalgets snitt for å kunne gjennomføre beregningene. Dette betyr at alle nedbrytninger er «rene».
- Output fra PageRank kan gjøres live, uten omfattende datakjøringer. Dette betyr at metoden egner seg godt til presentasjon i ulike dataverktøy.
Enkelte studier har antydet at PageRank også gir mer presise resultater enn HB. En overforenklet forklaring kan skissere hvordan:
La oss se for oss fire konkurrerende tennisspillere i en turnering:
Spiller 1, Spiller 2, Spiller 3 og Spiller 4 – rangert.
Hvis Spiller 3 ble beseiret av både Spiller 2 og Spiller 4, så kan vi anta at Spiller 3 er dårligst.
Men: hvis Spiller 3 vinner over Spiller 1 (den beste), og Spiller 2 og Spiller 4 ikke vinner flere kamper, så kan vi si at Spiller 2 er bedre enn disse. Denne egenskapen til PageRank fremhever noe av forskjellene mellom HB og PageRank-estimeringer.
PageRank tar hensyn til viktigheten» av forbindelsen mellom alternativer. I tennis-eksempelet over betyr dette at estimeringen av utfallet av hver spillers kamp i turneringen tar hensyn til utfallet av hver de andre spillernes kampere, uavhengig av hverandre. HB derimot vil estimere basert på alle tilgjengelige tenniskamper i denne/eventuelt flere tennisturneringer. På denne måten er PageRank mer fokusert i sine beregninger, og vil ikke gi uriktige estimater som ikke egentlig har noe med denne spesifikke turneringen å gjøre.
Kontakt eventuelt Norstat for nærmere tekniske beskrivelser og «white paper». Hvis du ønsker analysetjenester vil vi sette deg i kontakt med våre gode samarbeidspartnere på området.
(Kilde: A real‑time network‑based approach for analysing best–worst data types: Ákos Münnich · Emese Vargáné Karsai · Jenő Nagy (2022)
Visualiseringer
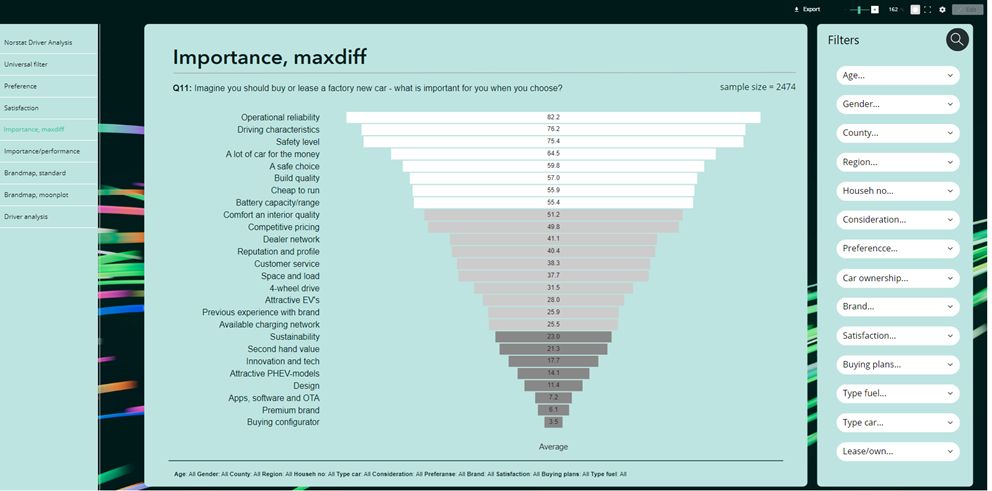
Den enkleste MaxDiff-visualiseringen er en graf som viser rangering av egenskapene. Derfra kan man utvikle det til nesten hva som helst, ikke minst dersom man benytter datavisualiseringer:
- Rangering kan brytes ned på hvilken som helst undergruppe.
- Sammenligning av viktighet på undergrupper.
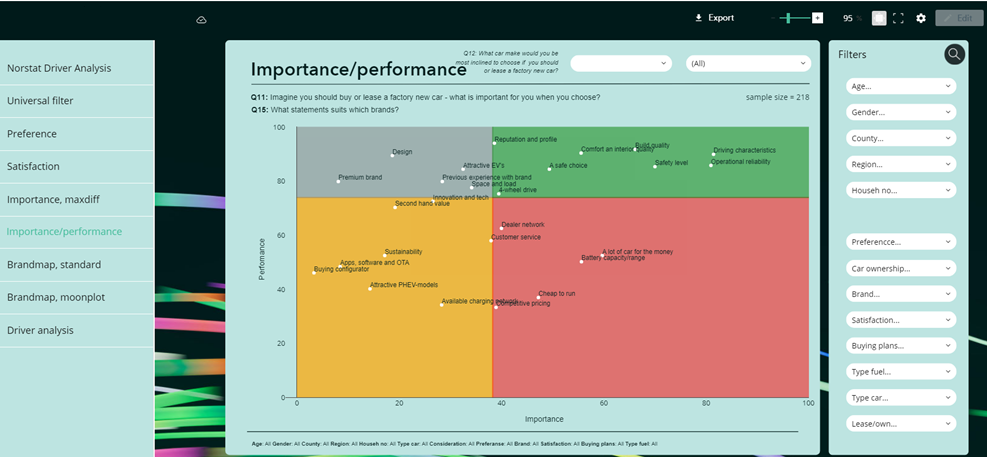
- Kan benyttes i viktighets-/dyktighets-matriser, der ene aksen baseres på gjennomsnittlig utility-score.
- Segmenteringsmodellering basert latent class-segmentering
- TURF-analyse (Total Unduplicated Reach and Frequency) basert på MaxDiff-resultater.
- Og mange, mange andre …
Eksempler på visninger
Rangering:
Viktighet/dyktighet:
Potensielle ulemper
Kompleks analyse: Analysen av MaxDiff-data er kompleks sammenlignet med skaladata. Det kreves spesialiserte statistiske teknikker for å utlede meningsfull innsikt fra dataene.
Begrenset informasjon: Respondentene blir presentert med et sett av egenskaper (ikke alle), noe som per definisjon begrenser informasjonen som er tilgjengelig for beslutningstaking. Dette kan bli sett på som en ulempe i enkelte prosjekter.
Undersøkelsesdesign: En MaxDiff-undersøkelse er avhengig av utformingen av eksperimentet, inkludert utvalget av egenskaper/drivere, og sammensetningen, for å fungere godt. Dårlig utformede studier kan føre til mindre pålitelige resultater.
Potensiale for feiltolkning: Tolking av MaxDiff-resultater krever nøye vurdering, og kan lede til feiltolkninger. Det er viktig å sikre at analysen utføres riktig for å kunne trekke gyldige konklusjoner.
Konklusjon
MaxDiff tilbyr en effektiv, gjennomprøvd og robust metode for å kartlegge preferanser og viktighet. Metoden krever teknisk kompetanse for oppsett, og verktøy, kompetanse og infrastruktur for tolkning og analyse av resultater. Output og resultater kan formateres og settes opp på forskjellige måter, det er her viktig å konsultere eksperter. I Norstat er vi ansvarlige for datainnsamlingen, mens våre kompetente samarbeidspartnere tar seg av analysearbeidet.
Brukt riktig er metoden et viktig tilskudd til sentrale beslutningsprosesser, og gir relevante og meningsfulle svar på kompliserte problemstillinger.
Annonse

Annonse
